
更新时间:2024-05-13 09:18:28点击:
了解更多短视频直播数据采集分析接口请点击查看接口文档
在抖音APP中根据关键词爬取响应视频的具体信息,主要包括视频标题、作者ID、视频url地址以及点赞数等。
在PC端安装安卓模拟器,模拟器很多,可随便选一个款就可以,我用的是雷电模拟器,模拟器一般都是自带root的。模拟器安装好后,然后进行一下配置 。 首先在命令窗口中输入ipconfig获取本机IP(注意:如果电脑连接的是无线网,IP就会根据的你无线地址变化)
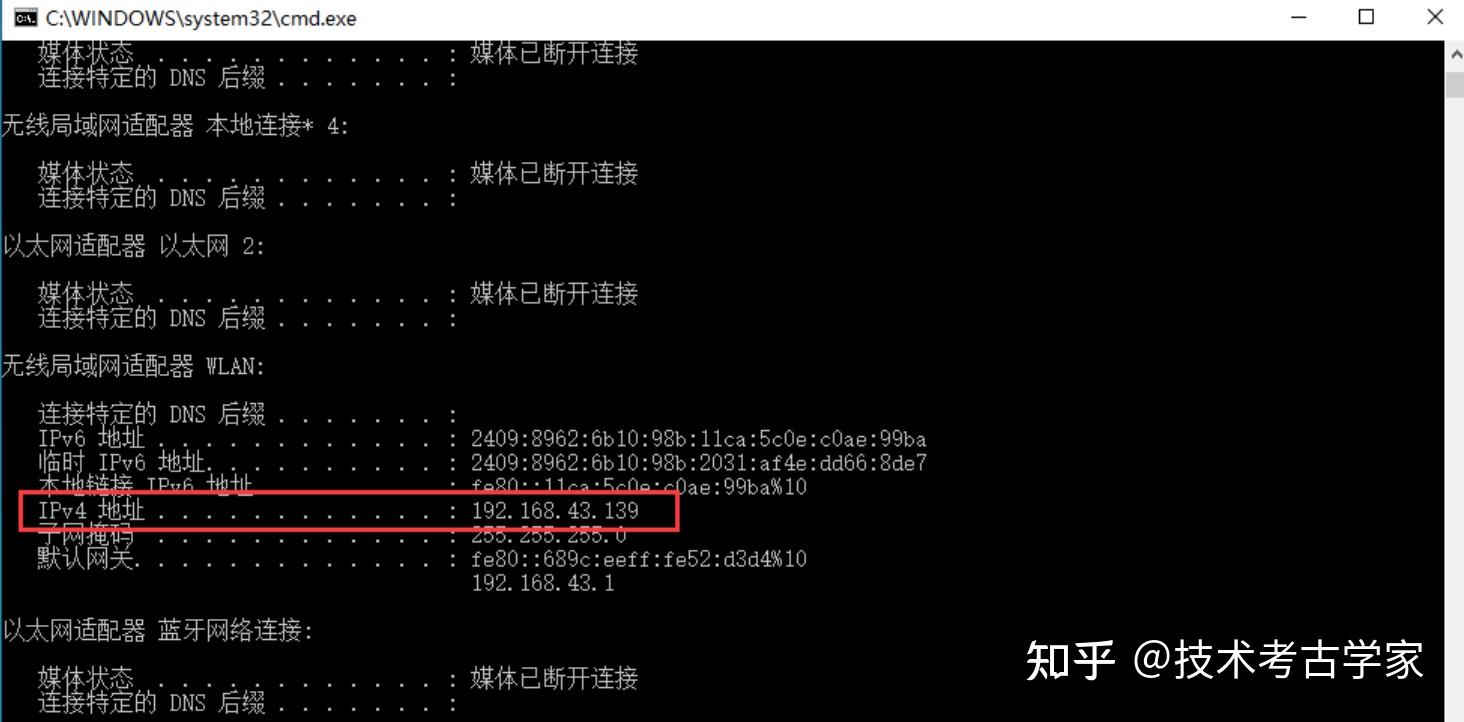
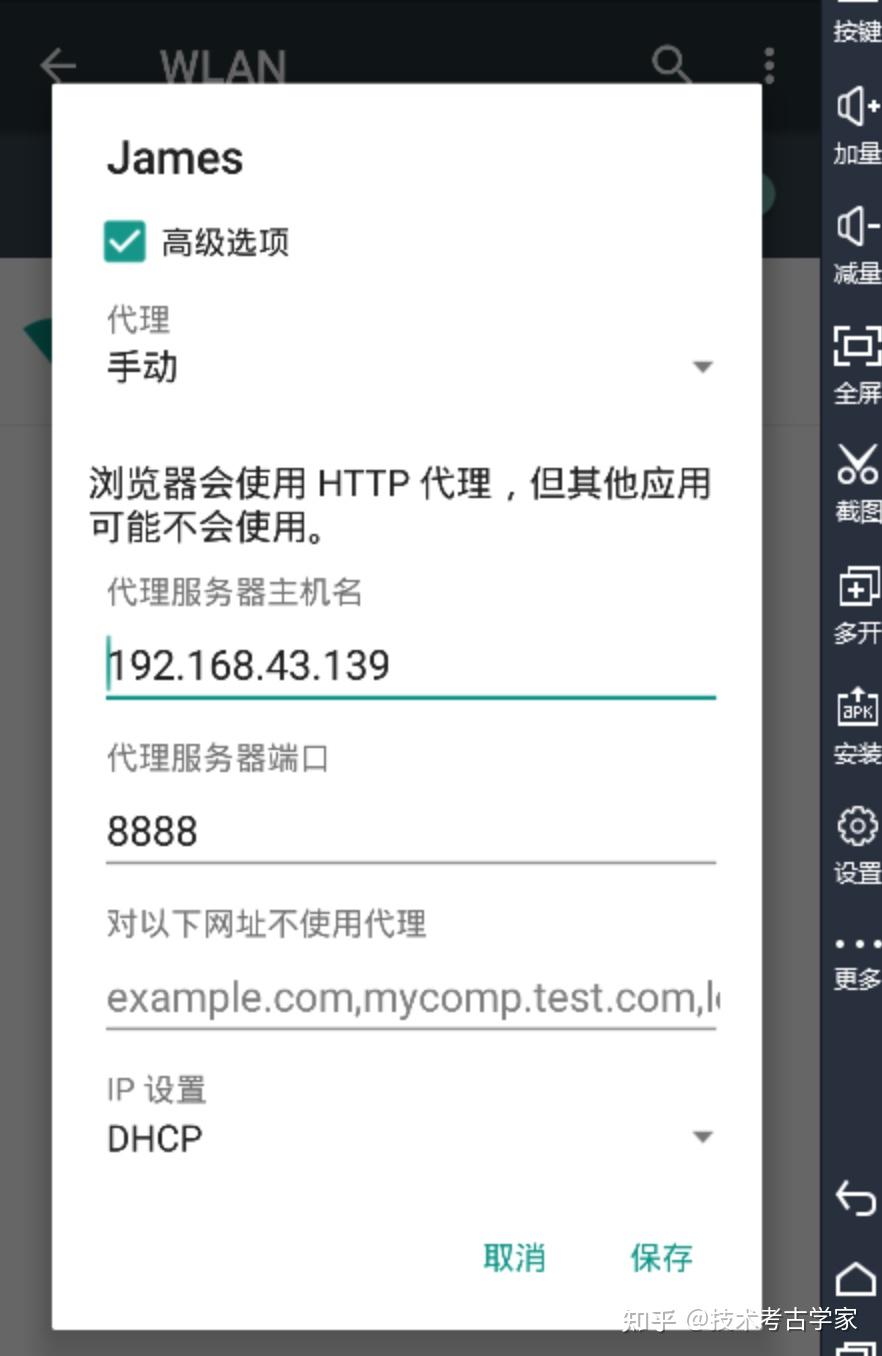
然后在设置模拟器代理(IP 要和上面的一致,不一致后面会导致APP不能上网)
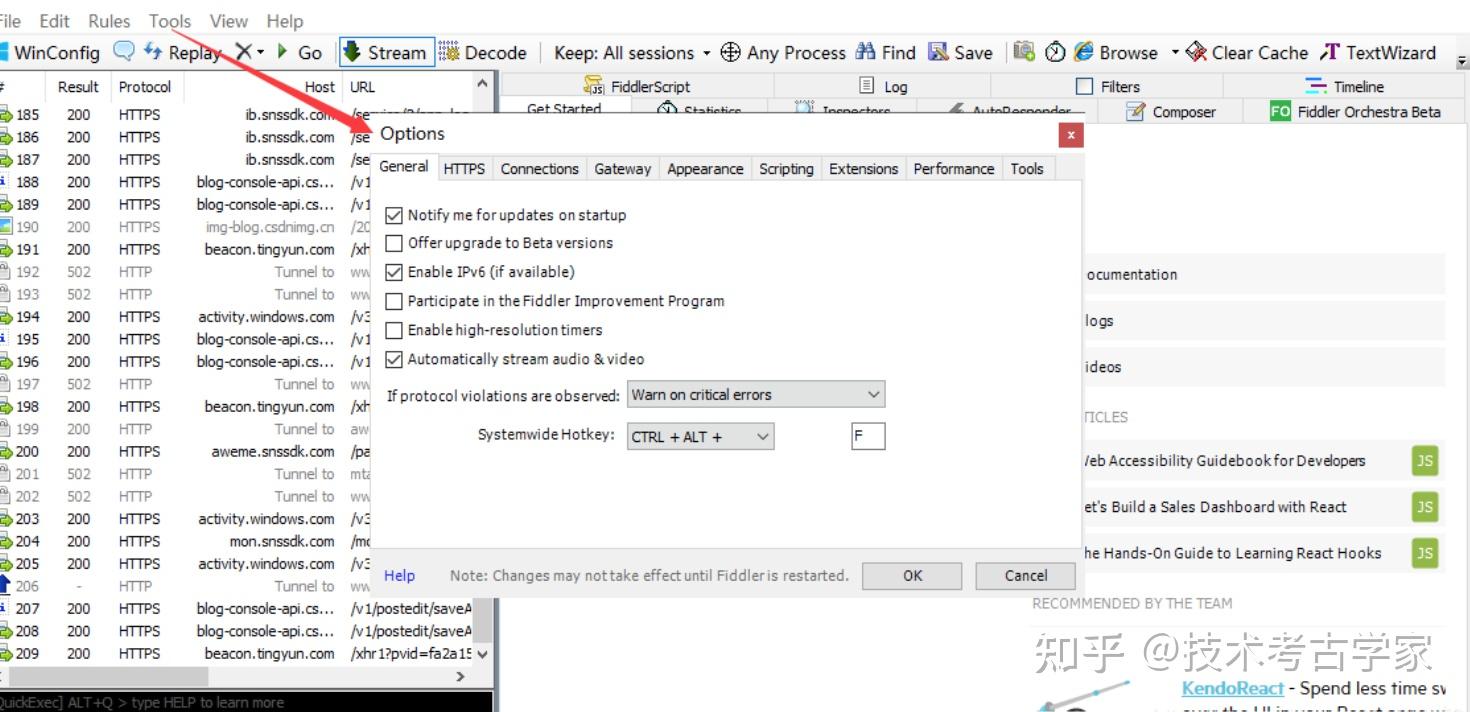
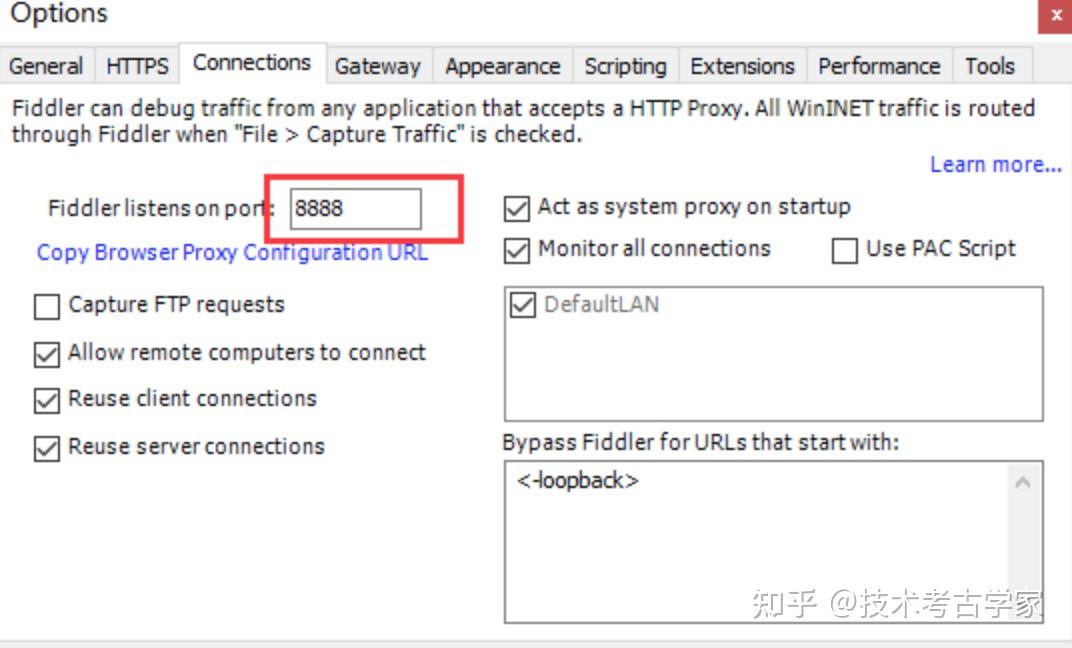
安装fiddler,具体安装步骤参考度娘,本项目中fiddler主要是用来抓包查看抖音的数据格式。对fiddler进行一下设置
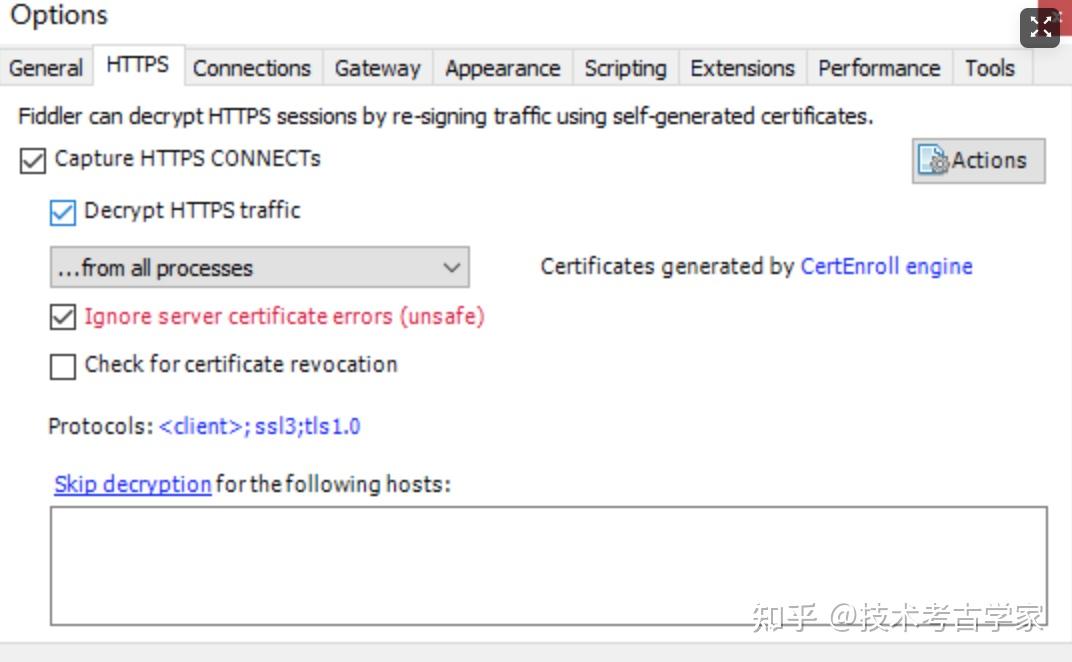
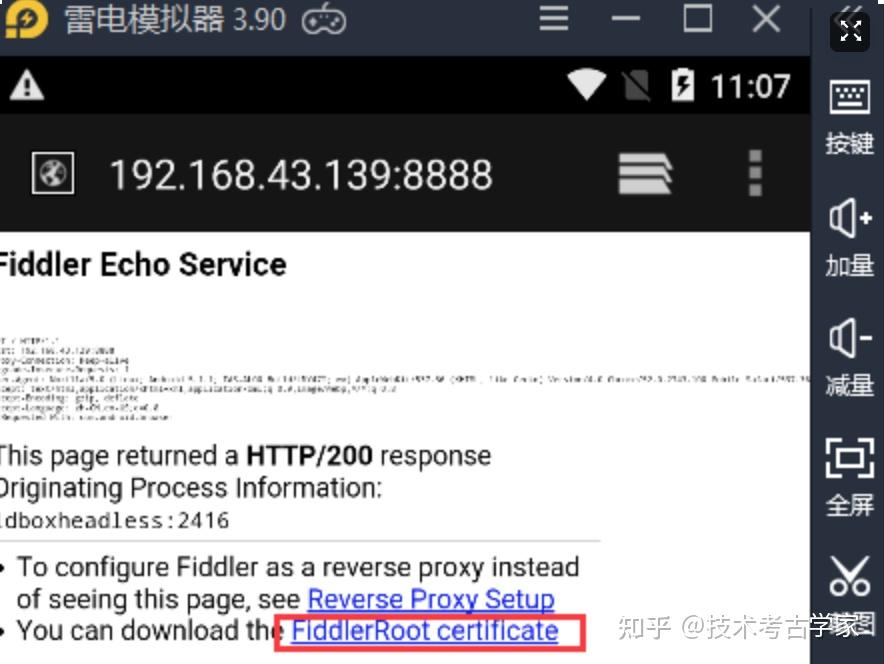
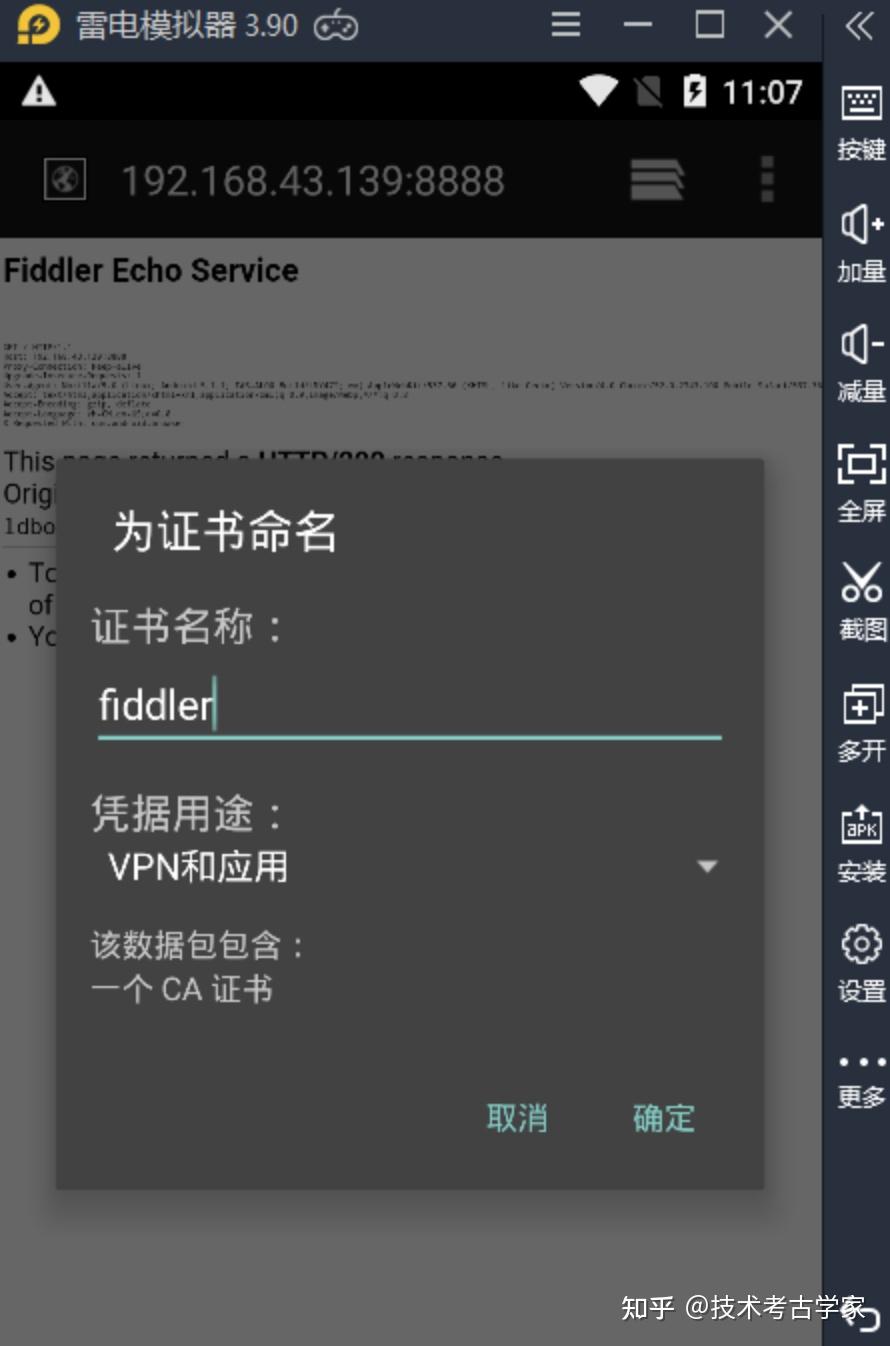
接下来安装fiddler证书,在模拟器中的浏览器中输入本机IP和端口号,下载并安装证书
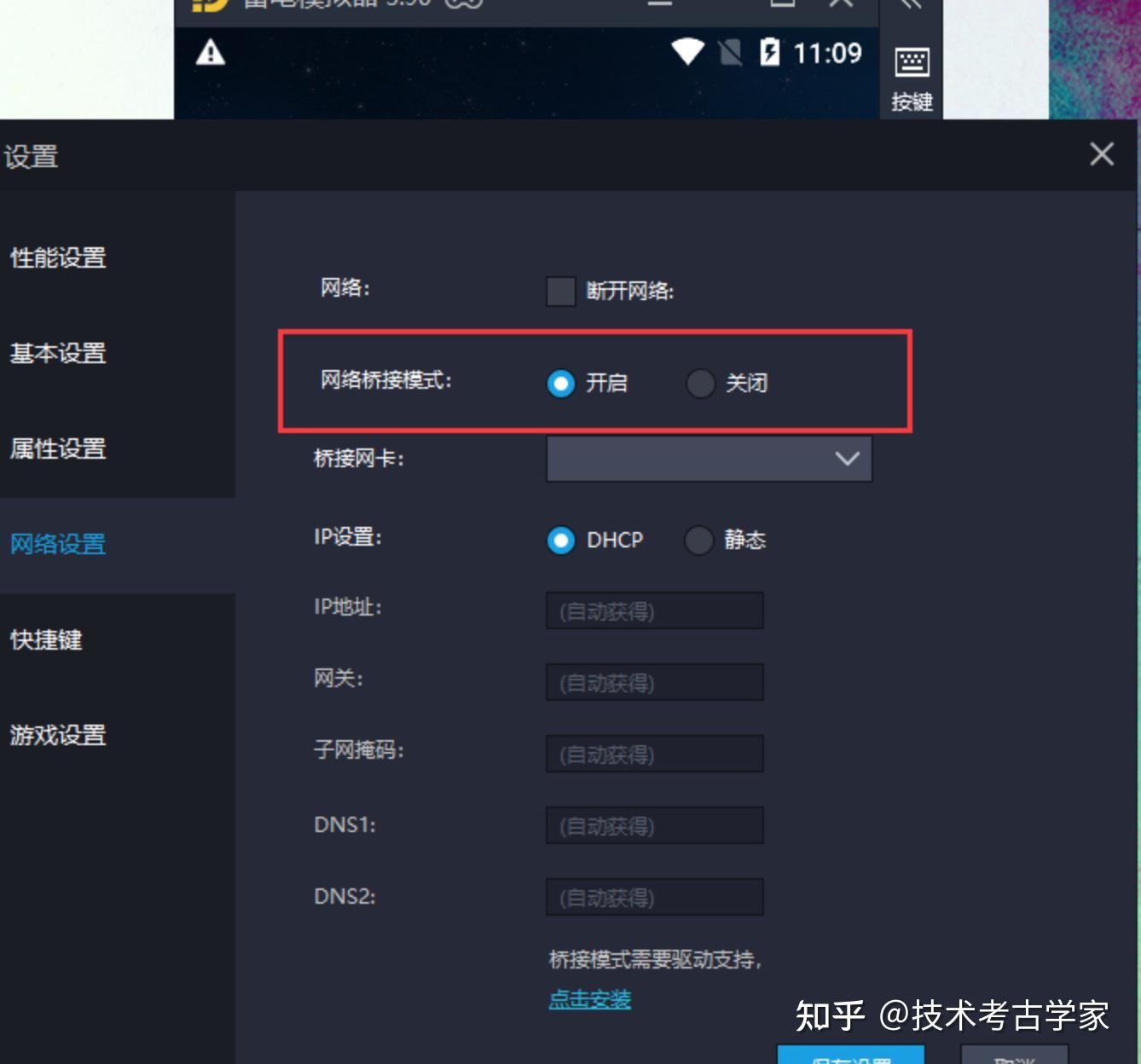
然后打开模拟器设置,开启桥接模式,不然后面会出现响应内容为空。
完成以上配置后,在命令行中输入mitmdump -p +端口号就可以启动服务了(注意:此时要关闭fiddler,不然会产生端口冲突)
为了是抖音能正常访问网络,还需要安装xposed框架的JustTrustMe组件
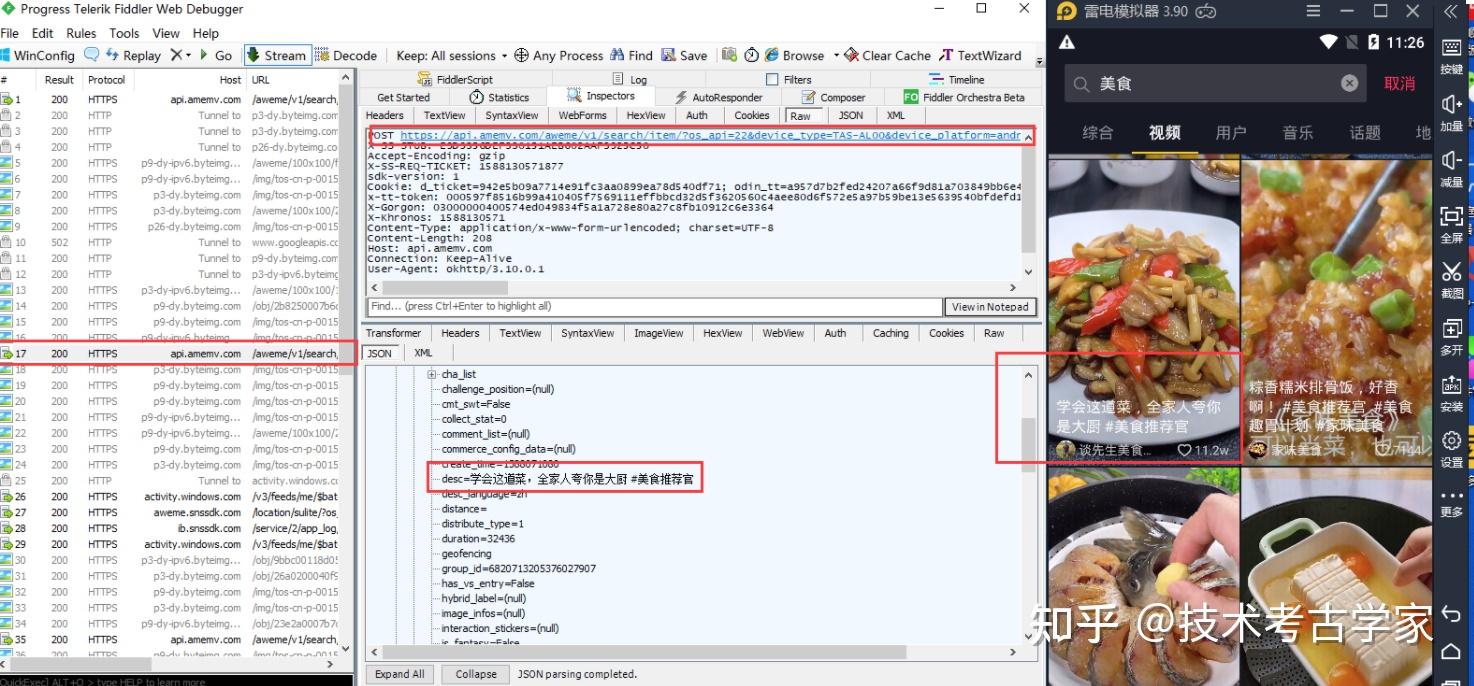
使用fiddler对抖音数据进行抓包,打开fiddler和抖音,向上滑动,获取更多视频,此时在fiddler中也会出现跟多的文件。找到POST请求中对抓到的数据进行分析,得到请求地址和数据格式。
知道url地址和数据格式之后,编写python程序,使用mitmdump抓包,当滑动屏幕就可以解析出数据。代码如下:
import json
import pandas as pd
import csv
import jsonpath
#函数名必须这样写 这是mitmdump规则
def response(flow):
#下面这个网址是通过fiddler获取到的 但是有些数据我们无法解密,所以需要用mitmdump捕获数据包然后做分析
if 'api.amemv.com/aweme/v1/search/item' in flow.request.url:
#将json数据转换为python对象
text = flow.response.text
data_json = json.loads(text)
#解析数据
for vedio in data_json.get('aweme_list'):
#构建有个空字典
vedio_info={}
#使用join去掉列表输出时存在的[],元素名前加*也是为了去掉输出数据带的''
#获取作者名字
author_list = [str(i) for i in jsonpath.jsonpath(vedio,'$..nickname')]
vedio_info['author_name'] = ''.join(*author_list)
#获取视频的评论数
comment_list = [str(i) for i in jsonpath.jsonpath(vedio,'$..comment_count')]
vedio_info['comment'] = ''.join(*comment_list)
#获取视频的点赞数
digg_list = [str(i) for i in jsonpath.jsonpath(vedio,'$..digg_count')]
vedio_info['digg'] = ''.join(*digg_list)
#获取作者的ID
vedio_info['author_id'] = vedio['author_user_id']
#获取视频的标题
vedio_info['vedio_title'] = vedio['desc']
#获取视频的url地址
vedio_info['vedio_url'] = vedio['share_url']
#打印视频的详细信息
print(vedio_info)
name_info = vedio_info['author_name']
comment_info = vedio_info['comment']
digg_info = vedio_info['digg']
author_info = vedio_info['author_id']
title_info = vedio_info['vedio_title']
url_info = vedio_info['vedio_url']
#newline的作用是防止每次插入都有空行
with open("food.csv", "a+", encoding='utf8',newline='') as csvfile:
writer = csv.writer(csvfile)
#以读的方式打开csv 用csv.reader方式判断是否存在标题。
with open("food.csv", "r", encoding='utf8',newline='') as f:
reader = csv.reader(f)
if not [row for row in reader]:
#先写入每一列的标题
writer.writerow(["name","author_id","comment_num","digg_num", "vedio_title", "vedio_url"])
#再写入每一列的内容
writer.writerows([[name_info,author_info,comment_info,digg_info,title_info,url_info]])
else:
writer.writerows([[name_info,author_info,comment_info,digg_info,title_info,url_info]])关闭fiddler,在命令窗口进入到.py文件的路径中,使用命令mitmdump -p 8888 -s douyin_vedio.py 回车运行,手动滑动屏幕就可以不断解析出更多的数据。
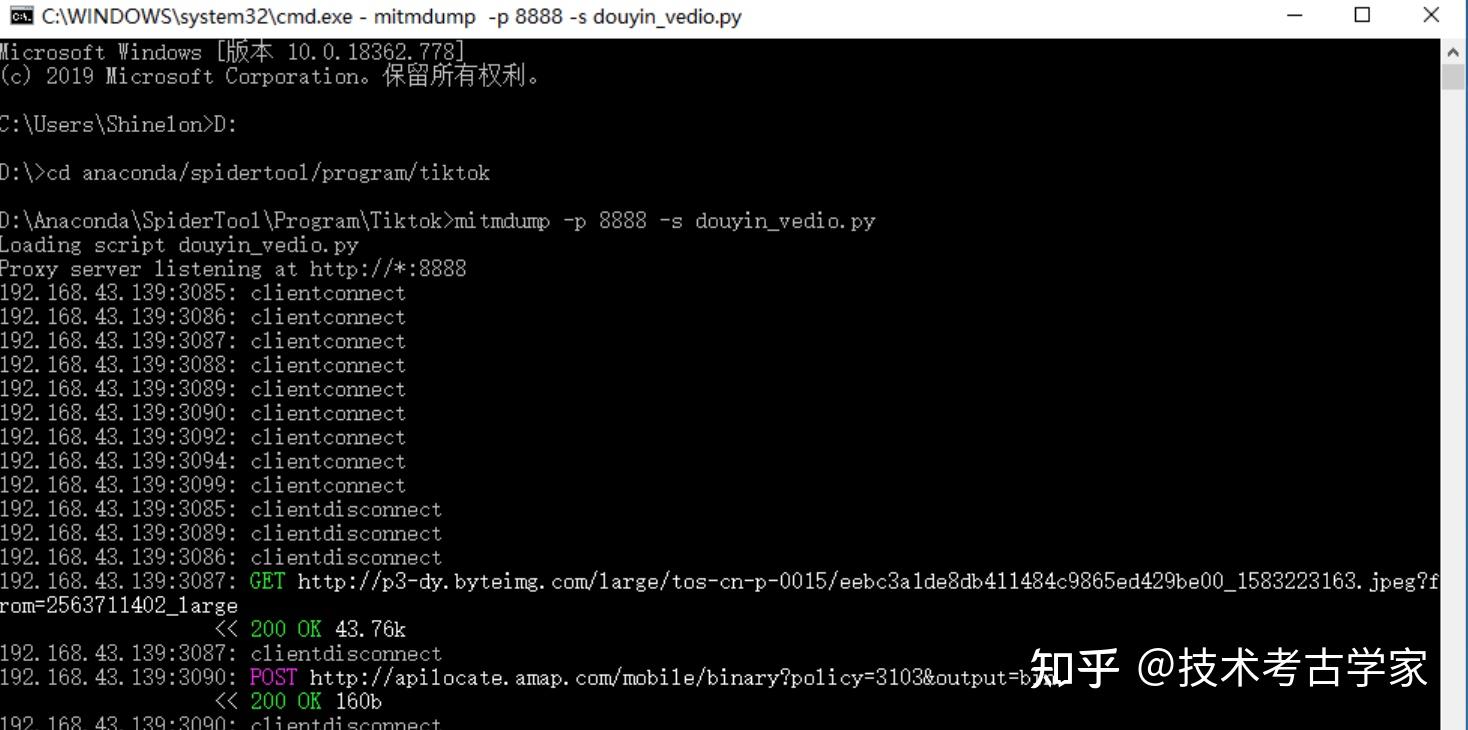
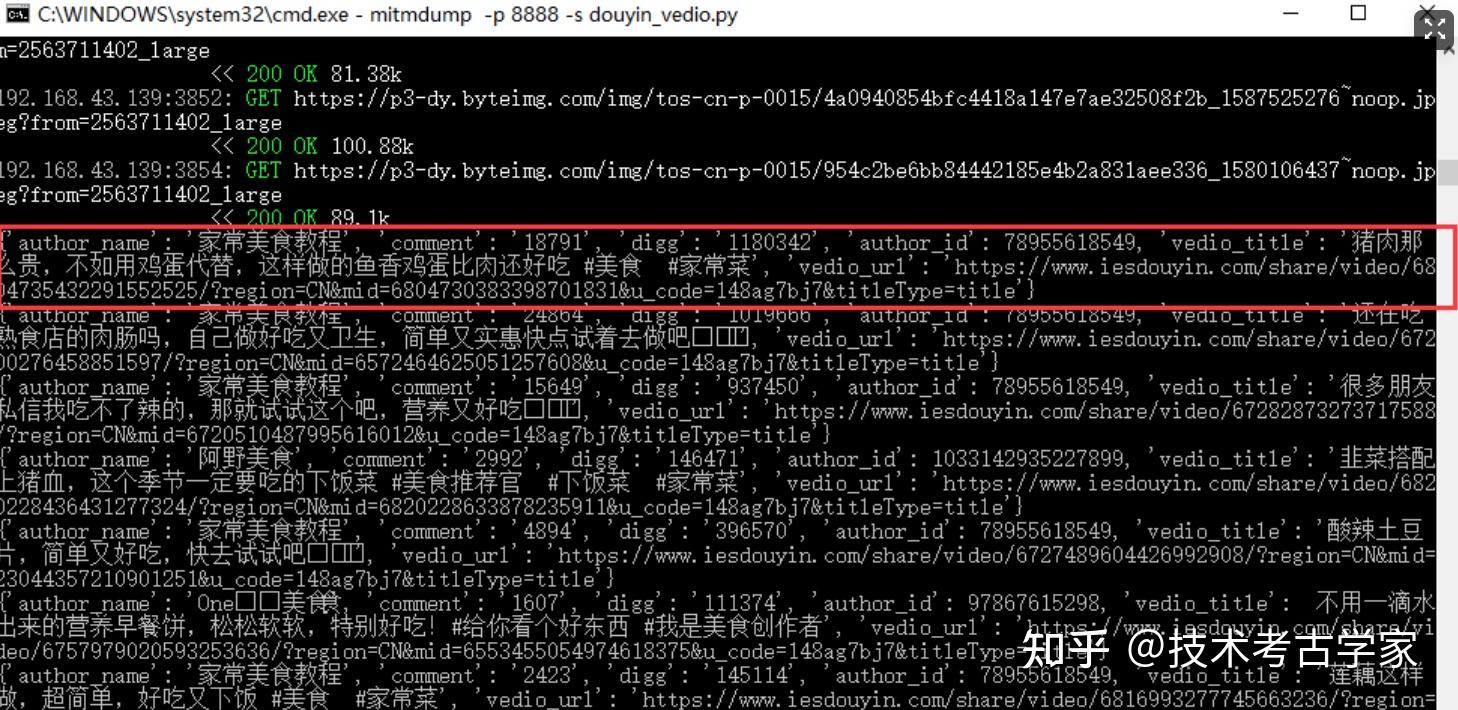
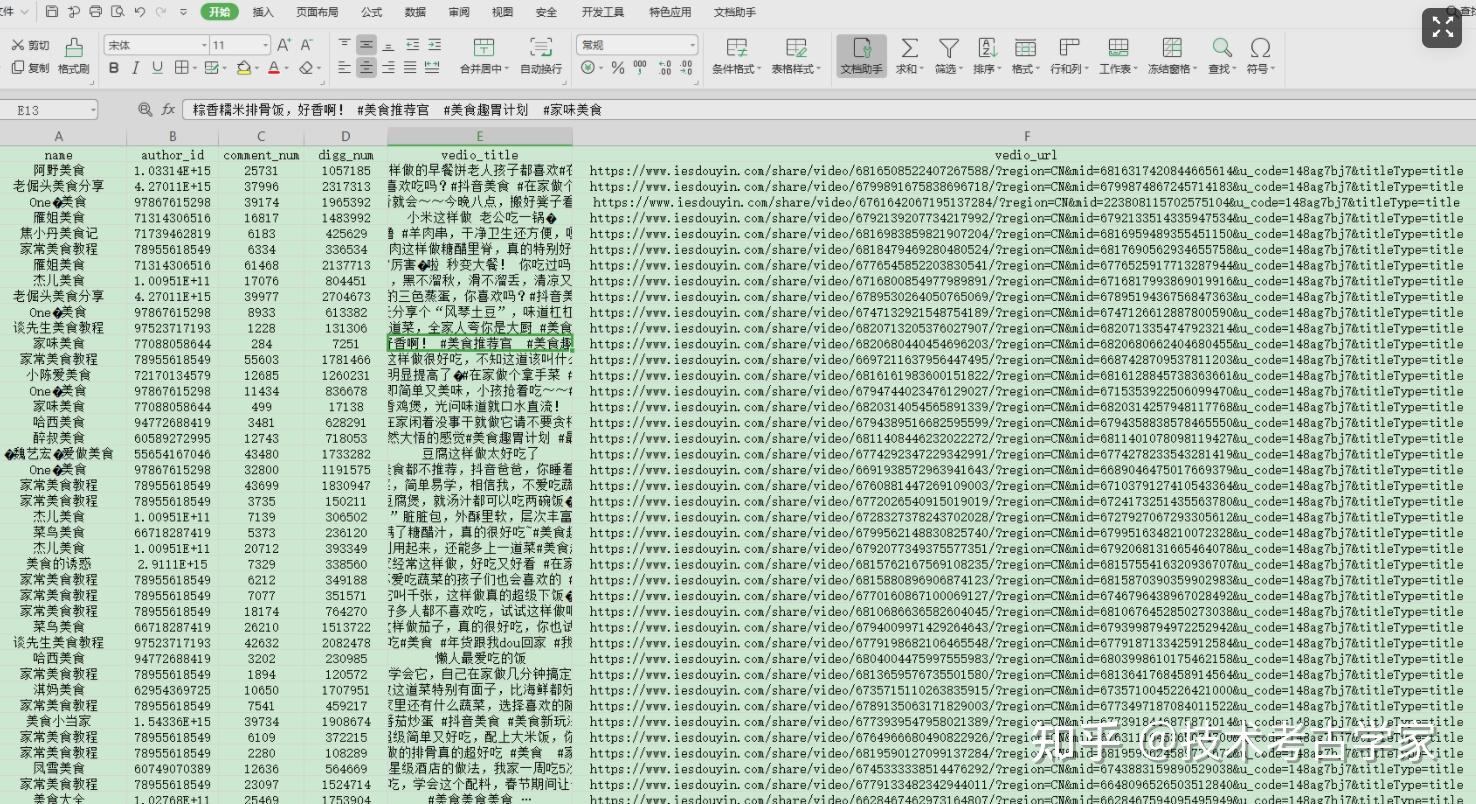
可以看到,上面已经得到了我们需要的内容,然后将数据存入到csv文件中。
如果数据量很大,手动滑动屏幕很麻烦,我们可以只用Appium进行自动化操作,实现包括打开抖音和自动滑屏等功能,我这里使用一个稍微简单的方法(实现功能就可以,手动狗头),使用Auto.js,编一些一个自动滑屏的脚本就可以实现自动滑屏了。要搞一下骚操作的话还是用Appium吧。
自动滑屏脚本,很简单
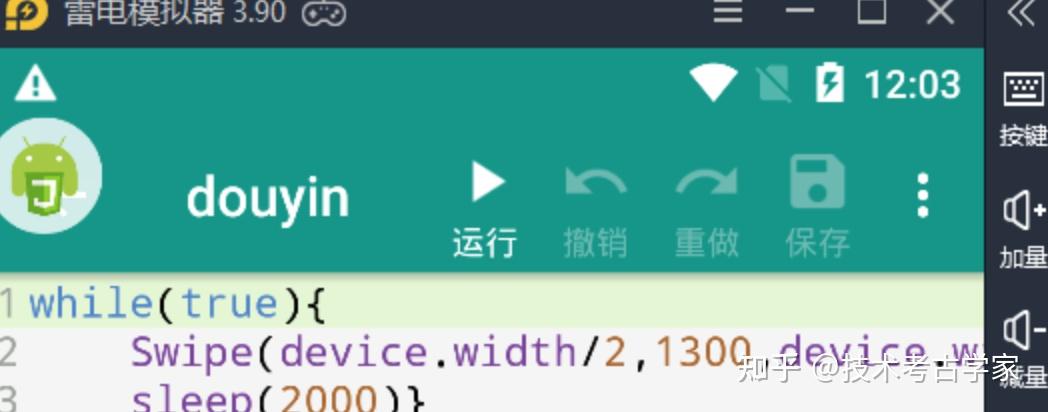
while(true){
Swipe(device.width/2,1300,device.width/2,300,2000);
sleep(2000)}打开Auto.js悬浮按钮,在抖音中运行自动滑屏脚本就可以了(注意:在Auto.js的设置中打开音量上键关闭停止所有脚本,不然会一致滑屏就无法正常使用模拟器了)
打开脚本后就可以看到视频在自动的滑动了。
大神们请略过,像我这种初学爬虫的弟弟,还是需要更多的耐心去学习。安装各种软件、配置环境和编写程序都会遇到各种各样的问题,重启可以解决百分之八九十的电脑故障问题,找度娘也可以解决你绝大多的问题,不管遇到什么问题就找度娘吧(看病除外)。
免责申明:此内容仅供学习交流使用,若侵犯贵方权益,请联系作者删除







